Jekyll2023-07-29T12:54:53+02:00https://guzalexander.com/feed.xmlAlexander Guz’s blogAlexander GuzThe age of average — Alex Murrell2023-04-12T14:10:00+02:002023-04-12T14:10:00+02:00https://guzalexander.com/2023/04/12/link-to-averagePeople just want to have the same stuff.]]>Alexander GuzRemNote — Great Note-Taking App Nobody is Talking About2020-09-11T21:30:00+02:002020-09-11T21:30:00+02:00https://guzalexander.com/2020/09/11/notes-apps-fatigueI have been using Evernote for quite some years now as my go-to application for
notes, bookmarks, sketches, etc. Indeed, it is not a bad choice: clients for all platforms
you can imagine, synchronization between devices, good enough editor with formatting,
typical hierarchical notes organization into notebooks and sub-notebooks, tags, sharing
options, etc. I even had a paid version in order to have synchronization on more than two
devices. And still, I have never felt that I have been using all its potential.
Eventually, I realized that my notes were lying “dead“ there. Like a pile of useless crap.
Basically, once something got into Evernote, I just forgot about it. And, probably, never
open this note again, except for some edge cases. These notes were not helping me.
Then I stumbled upon Roam Research – the app on hype now. It had invitation system,
so I could only check out the demo page.
But it was not the tool itself that made me switch from Evernote. By watching tutorials,
and reading articles about Roam I grasped the idea of a second brain, a personal
knowledge base. This is where it all clicked – my Evernote notes are junk, because they
are not connected to each other. Yes, I have a notebook “Programming“, but notes inside this
notebook are just separate pieces with no relation to each other whatsoever. These
relations exist only in my head. And my head has only so much free space to hold all
this stuff.
Roam Research
The essential part that is missing in Evernote in comparison to, let’s say the same Roam
Research, is linking of the notes. One can argue, that Evernote has notes links. But
functionality- and comfort-wise they are a joke. Imagine, you are writing a note about
new sorting algorithm, and now you want to link some phrase to the big-O notation note.
You have to:
1. Find big-O note (potentially in another notebook).
2. Then right click and find an option to copy the note link.
3. Then go back to the place where you want to place the link and
4. Finally, paste it.
I almost died from boredom by just explaining this procedure. By the time you finish it,
you have already lost any thought train you had.
Just to have a link inside a note to another note is not enough, though. Another powerful
concept is back linking. Imagine, you are looking at a note, and you can immediately see
if any other note refers to it. You might have linked it from another place without putting
too much thought, but in the end you created a new association that can create a new idea.
Pretty cool. Some apps go further and even provide so called “non-referenced“ links, i.e.
they show other notes that reference just the title of the current note as a text.
I was hooked and decided to switch. But first, I needed to find the perfect application,
of course. Roam Research is too expensive. I mean, I am glad to spend $15/month for an
app, if I know that this is a game changer. But not from the day one. So I started my
research. Oh boy, just look at this huge list of 85 note-taking applications! I think I have
looked almost through all of them, and fooled around with at least 15 or so.
RemNote is great. It is free. It is packed with features. It is ugly. Well, to be
fair it was ugly until the recent upgrade a few days ago. Now it is a bit better. But I
like the spirit. Started to use it on a daily basis. Cancelled my Evernote subscription.
It is a long way for RemNote to become great, though. What they currently lack is media
promotion. This is a great application nobody is talking about! Everybody talks
only about Roam Research.
RemNote tutorial page
So did I just find a perfect tool for me? I am not sure, to be honest. RemNote has a bunch
of downsides. For example, lack of a desktop application that is huge minus for me, since
I hate doing serious work in a browser window. I also have some concerns about the future
of the app: there is no business behind, and I cannot tell for sure how serious the authors
are about continuing working on it. I definitely don’t want to lose all my notes in two years or so.
And let’s not forget, that there are other players on the market. There are so many options!
Having so much variety might seem like a good thing in the first place, but it leads to
decision fatigue. I really just want
to have the work done, to have my brain organized and get the most out of my notes. I
don’t want to spend endless hours on choosing the right tool.
]]>Alexander GuzPastel Interfaces2020-09-04T20:30:00+02:002020-09-04T20:30:00+02:00https://guzalexander.com/2020/09/04/pastelI prefer light color themes in application interfaces. Never understood this craze about
dark interfaces. As I spend a lot of time in a code editor, I believe light colors are
easier for my eyes. But, not the point.
Recently I noticed that in some applications – Firefox, IntelliJ IDEA, for example, – I
switched to new color themes that looks similar to each other. Here is
the Calm Pastel 4 theme for Firefox:
Calm Pastel 4
And here is the Pastel-licious for IntelliJ IDEA (I love this theme!):
Pastel-licious
Both of these themes are in one color palette – pastel. But what does this word even mean?!
I have heard multiple times things like “to draw with pastel“, or this picture is in
pastel tones, etc. But I had only vague idea about what that meant. So I decided to dig
a bit.
So the word “pastel“ comes from Italian “pastello“, that comes from Italian “pasta“. Nice,
I love Bolognese. Hm, wait, it’s not about food here… Anyway, pastel is both a name for
an art medium in the form of a stick and a drawing technique. It is used during the
preparation phase for paintings, but some artists use it as a standalone art form. It is
only possible with the usage of special fixative, since pastel material is very easy
to destroy. One of the most prominent pastels is The Chocolate Girl:
By Jean-Étienne Liotard
But I digress. I will not go really deep into that. You better just read it in
Wikipedia. What drives my attention to these type
of themes is pastel colors. This is a
palette of muted pale shades with high value and low saturation.
Example of pastel palette
All these colors have one common characteristic: they are soft to the eye, calm, warm.
They do not irritate our eyes and do not distract, letting your eyes relax. Seems like
I am choosing these type of color theme subconsciously – it is just easy and pleasant
to look at such interfaces for a long time.
]]>Alexander GuzGPS Art2020-08-30T21:30:00+02:002020-08-30T21:30:00+02:00https://guzalexander.com/2020/08/30/gps-artI bet everybody knows this feeling when you get an interesting idea in your head, and
you think – that is it! I need to do it! You start to dig into, but the first Google
request shows that somebody has already implemented it. Bummer. I had one of those ideas
the other day.
Since around a year or a bit more, I am into running. For tracking my running time and
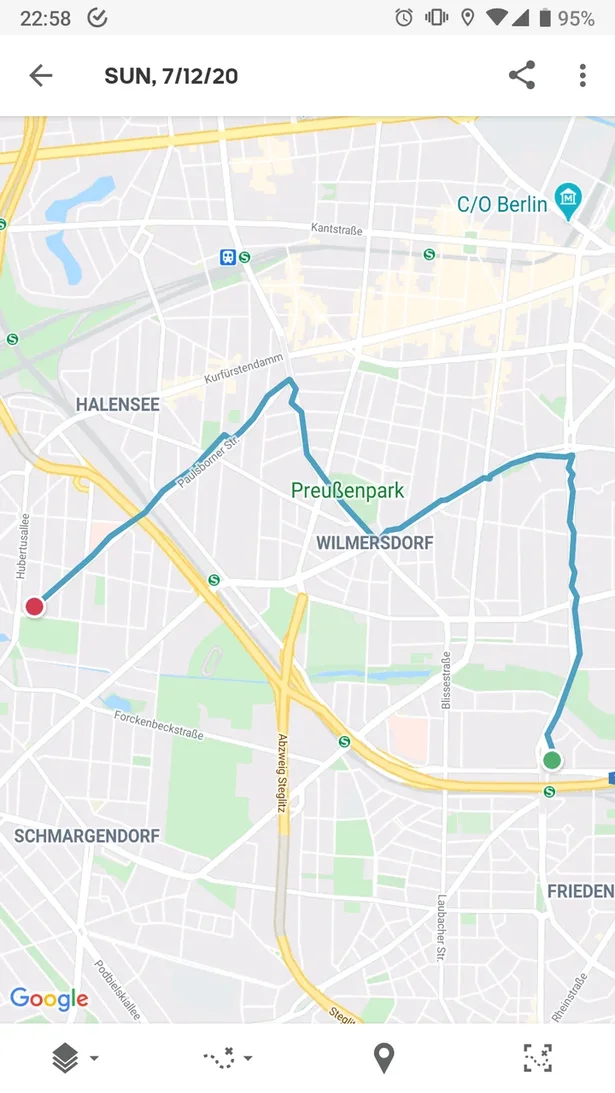
routes I am using an application, of course. It is nice to look at some statistics. After
one of the runs, I looked at the route, and it reminded me of some figure or a drawing.
And then a thought came to me – what if we draw something on a map while running using a
GPS tracker?! Just imagine: a whole community running and sharing their routes!
My first deliberate attempt to draw during running was a letter “M“. It is supposed to be
the first letter in either my wife’s name, or in the word “Metallica“. I’m not sure yet.
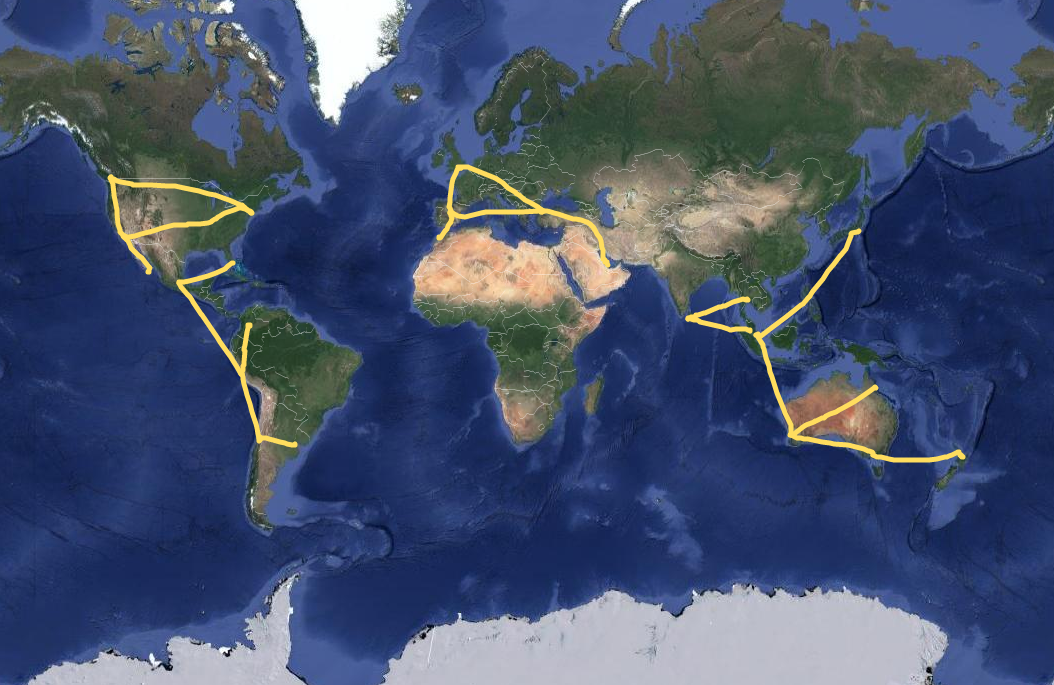
As it turned out, I am not the only one to come up with this idea. Drawing on a map with
a GPS tracker is called GPS Art. It originated in 90s, and, of course, became more
popular with a spread of mobile GPS devices. Check out hashtag #gpsart
on Twitter for inspiration.
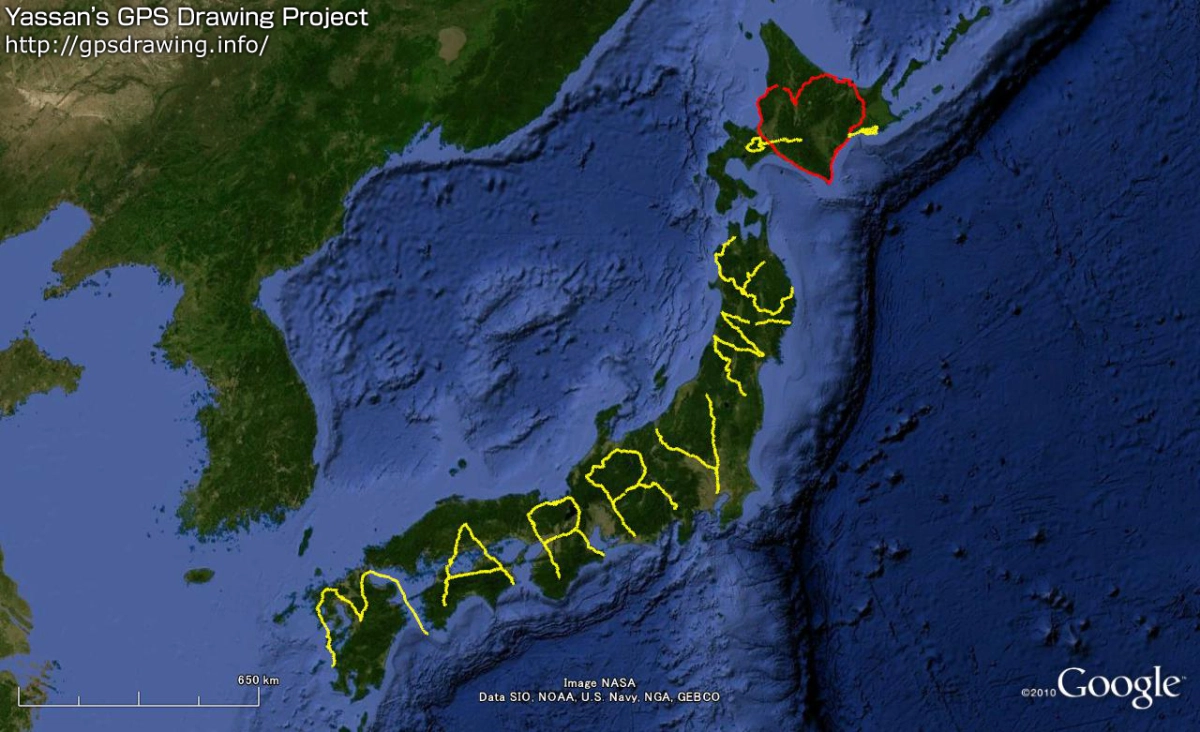
The community also has its heroes. For example, the largest drawings on Earth belong to
Japanese artist Yasushi Takahashi. Here is a word “peace“… 60,794 km long.
But anyway, a journey of a thousand miles begins with a single step. So I guess I just go
put my running shoes on and take a bunch of those single steps for now.
]]>Alexander GuzOn Being a Backbone Software Developer2020-08-26T21:00:00+02:002020-08-26T21:00:00+02:00https://guzalexander.com/2020/08/26/ace-pilotsPilots performing aerobatics maneuvers at air shows are exceptional professionals with
incredible skills. I witnessed with my own eyes the Cobra maneuver at one of the
performances in Moscow. It is indeed an incredible sight. Piloting at its best.
At the same time, a thought came to me: How often do pilots use these aerobatics maneuvers
in real conditions? I doubt these skills are required during another planned flight.
And my next thought was: Despite the skills, these pilots are not the backbone of a
regular army. Regular pilots — work horses — serve as a basis for any unit. They do the job
without frills. Perhaps, they are not that good at air shows, but it doesn’t make them less
important.
We observe the same situation in software development. Ace pilots are programmers who
solve whiteboard puzzles. But are they a good fit for a regular job? Anyone who was hiring
at and conducting interviews knows that these whiteboard skills do not automatically mean
good performance when working on a project in a team.
As it is with pilots, the backbone of any team or organization bases on ordinary
programmers. They are not rockstar developers. They might not invert a binary tree in
their head. But they solve specific tasks by googling and coping from StackOverflow.
Backbone developers deliver.
Being the backbone is not a shame. It is honorable.
]]>Alexander GuzWelcome to March 32nd2020-05-03T14:00:00+02:002020-05-03T14:00:00+02:00https://guzalexander.com/2020/05/03/oversize-date-mechanismMy wife and I both have watches with the date window - the one that shows the day of the month. At the end of March,
nearly midnight, my watch’s date window switched to number “1”, which stands for April 1st. Though my wife’s watch
started to show number “32” instead. I was curious why, and found out that it is because of so called outsize date
mechanism.
The standard date mechanism is made of a single ring with numbers from 1 to 31 printed on it. The ring gradually rotates,
and eventually switches to another number. My watch has this mechanism. The “problem” is that this way the window size,
and thus the size of a number inside, is small, because the ring has to fit into the frame.
The feature that allows to have a larger “font size” in date windows goes under the name
the oversize date complication.
This feature utilizes two pieces for displaying the date: units disc and tens cross, which are nicely synchronized.
Tens cross has numbers from 0 to 3, and unit disc - from 0 to 9. The final day of the month is then a combination of two
digits from both pieces.
This video has a nice visual explanation of the outsize date mechanism.
So why does my wife’s watch show 32? Well, it actually goes up to 39! It seems that in some “cheap” implementations of
the oversize date mechanism, the tens cross and the unit disc do not have proper synchronization. After the tens cross
switched from 3 to 0, indicating the beginning of a new month, the unit disc just continues to rotate further to 2, 3, 4, etc.
]]>Alexander GuzCovariance and Contravariance in Programming2020-02-04T09:00:00+01:002020-02-04T09:00:00+01:00https://guzalexander.com/2020/02/04/variance-in-type-systemsWhenever I hear “covariant return type”, I have to pause and engage my
System 2 thoroughly in order to understand what I have just heard.
And even then, I cannot bet I will answer properly what it means. So this serves
as a memo for me of the concept of variance in programming.
The notion of variance is related to the topic of subtyping in
programming language theory. It deals with rules of what is allowed or not with
regards to function arguments and return types.
Variance comes in four forms:
invariance
covariance
contravariance
bivariance (will skip that)
Before we dive into explanations, let us agree on pseudo code that I am going
to use. The > operator shows subtyping. In the example
Vehicle > Bus
Bus is a subtype of Vehicle. Functions are defined with the following syntax:
func foo(T): R
where T is a type of an argument, and R is a return type of a function foo.
Functions can also override another functions (think “override of a method
in Java”). Here, bar overrides foo:
func foo(T): R > func bar(T): R
Throughout the example, I will be using this hierarchy of objects.
Vehicle > MotorVehicle > Bus
Invariance
Invariance is the easiest to understand: it does not allow anything - neither
supertype nor subtype - to be used instead of a defined function argument or
return type in inherited functions. For instance, if we have a function:
func drive(MotorVehicle)
Then the only possible way to define an inherited function is with MotorVehicle
argument, but not Vehicle or Bus.
This way, the type system of a language doesn’t allow you much flexibility,
but protects you from many possible type errors.
Covariance
Covariance allows subtypes or, in other words, more specific types to be used
instead of a defined function argument or return type. Let’s start with return
types. Return types are covariant. Let’s look at these two functions:
func produce(): MotorVehicle > fn overrideProduce(): Bus
Is it OK that overrideProduce returns more concrete Bus instead of
MotorVehicle? Yes, it is! Since Bus is a type of MotorVehicle, it meets
the contract, because it supports everything a MotorVehicle can do. So this
is allowed:
This is actually not allowed by a safe type system, because overrideDrive
breaks parent’s contract. Users of drive expect to be able to pass any type
of MotorVehicle, not only Bus. Indeed, imagine someone calls drive with,
let’s say a Car (where MotorVehicle > Car), then the call to overrideDrive
will be overrideDrive(Car), but overrideDrive works only with Bus instances.
So function arguments are not covariant. And here we approach contravariance.
Contravariance
Contravariance allows supertypes or, in other words, more abstract types to be
used instead of a defined type. Function arguments are contravariant.
Let’s have a look at the example.
Though it looks counterintuitive, this is a perfectly valid case.
overrideDrive meets parent’s contract: it supports any Vehicle, and since
MotorVehicle is a type of Vehicle, users of drive still can pass any
instance of MotorVehicle.
]]>Alexander GuzBooks I Read in 20192020-01-10T21:40:00+01:002020-01-10T21:40:00+01:00https://guzalexander.com/2020/01/10/books-read-20192019 is the first year I decided to track books I have read on Goodreads. Here is the list. Though, it might be not complete, because I got this idea only in December and struggled to recall all the books.
Quite clear that fiction prevails. Definitely will spend more time reading more useful books this year.
]]>Alexander GuzJava Geospatial In-memory Index2018-11-04T19:12:00+01:002018-11-04T19:12:00+01:00https://guzalexander.com/2018/11/04/java-in-memory-geospatialOne of my recent tasks included searching for objects within some radius based on their geo coordinates.
For various reasons — not relevant to this topic — I wanted to make this work completely in
memory.
That’s why solutions like MySQL Spatial Data Types, PostGIS or Elasticsearch Geo Queries were not considered. The project is in Java. I started to look for possible options, and, though, I found a few, they all lacked an easy to follow documentation (if at all) and examples.
So I decided to make a short description of some Java in-memory geospatial indices I’ve discovered during my research with code examples and benchmarks done with jmh.
Again, the task at hand: given a geo point, find the nearest to it object within a given radius using in-memory data structures. As an extra requirement, we would like to have arbitrary data attached to the objects stored in this data structures. The reason is that, in most cases, these objects are not merely geo points, they are rather some domain entities, and we would build our business logic based on them. In our case, the arbitrary data will be just an integer ID, and we pretend we can later fetch required entity from some repository by this ID.
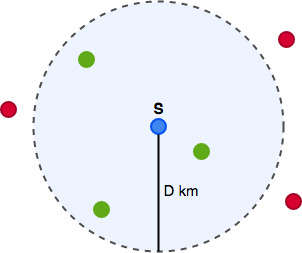
Figure 1. We need to find all green points within the radius of D km from the source point S.
Lucene spatial extras
I learned about Lucene while using Elasticsearch, because it’s based on it. I thought: well,
Elasticsearch has Geo queries made with Lucene, which means Lucene has support for it, which, maybe, also has support for in-memory geospatial index. And I was right. Lucene project has Spatial-Extras module, that encapsulates an approach to indexing and searching based on shapes.
Using this module turned out to be a non-trivial task. Except JavaDocs and source code, I could only find an example of its usage in Apache Solr + Lucene repository, and made my implementation based on it. Lucene provides generalised approach to indexing and searching different types of data, and geospatial index is just one of the flavours.
Let’s have a look at the example.
finalSpatialContextspatialCxt=SpatialContext.GEO;finalShapeFactoryshapeFactory=spatialCxt.getShapeFactory();finalSpatialStrategycoordinatesStrategy=newRecursivePrefixTreeStrategy(newGeohashPrefixTree(spatialCxt,5),"coordinates");// Create an indexfinalDirectorydirectory=newRAMDirectory();IndexWriterConfigiwConfig=newIndexWriterConfig();IndexWriterindexWriter=newIndexWriter(directory,iwConfig);// Index some documentsvarr=newRandom();for(inti=0;i<3000;i++){doublelatitude=ThreadLocalRandom.current().nextDouble(50.4D,51.4D);doublelongitude=ThreadLocalRandom.current().nextDouble(8.2D,11.2D);Documentdoc=newDocument();doc.add(newStoredField("id",r.nextInt()));varpoint=shapeFactory.pointXY(longitude,latitude);for(varfield:coordinatesStrategy.createIndexableFields(point)){doc.add(field);}doc.add(newStoredField(coordinatesStrategy.getFieldName(),latitude+":"+longitude));indexWriter.addDocument(doc);}indexWriter.forceMerge(1);indexWriter.close();// Query the indexfinalIndexReaderindexReader=DirectoryReader.open(directory);IndexSearcherindexSearcher=newIndexSearcher(indexReader);doublelatitude=ThreadLocalRandom.current().nextDouble(50.4D,51.4D);doublelongitude=ThreadLocalRandom.current().nextDouble(8.2D,11.2D);finaldoubleNEARBY_RADIUS_DEGREE=DistanceUtils.dist2Degrees(100,DistanceUtils.EARTH_MEAN_RADIUS_KM);finalvarspatialArgs=newSpatialArgs(SpatialOperation.IsWithin,shapeFactory.circle(longitude,latitude,NEARBY_RADIUS_DEGREE));finalQueryq=coordinatesStrategy.makeQuery(spatialArgs);try{finalTopDocstopDocs=indexSearcher.search(q,1);if(topDocs.totalHits==0){return;}vardoc=indexSearcher.doc(topDocs.scoreDocs[0].doc);varid=doc.getField("id").numericValue();}catch(IOExceptione){e.printStackTrace();}
In order to use it we need:
Create an index. At this step you can choose where to store the index. For our use case, there is a RAMDirectory, which is essentially in-memory storage. This class is marked as deprecated, because it uses inefficient synchronization according to the documentation. This might explain its poor performance. But we’ll come back to this later.
Index some documents. To make our index support geospatial queries we need to have a field of type Shape, in particular Point in our document.
Query the index. Perform a spatial operation against the index.
Oh my gosh! That’s a good deal of classes to consider! That is definitely not the winner of the contest on “The most clear and easy to use API”. Though, as you would expect, Lucene indices are the most flexible:
Provides various shapes implementations: point, rectangle, and circle. You can also teach it to support polygons with some additional dependency.
You can put any data to the indexed document along with its geo point. It means you can store the whole entity there and perform other queries supported by Lucene, for example, fuzzy text matching.
Supports various spartial operations: is within, contains, intersects, etc. Check SpatialOperation.
It has distance and other spatial related math calculations.
Jeospatial
Jeospatial is a geospatial library that provides a set of
tools for solving the k-nearest-neighbor problem on the earth’s surface. It is implemented using
Vantage-point trees, and claims to have O(n log(n))
time complexity for indexing operations and O(log(n))— for searching. A great visual explanation of how Vantage-point trees are constructed with examples can be found in this article.
Figure 2. An illustration of a Vantage-point tree.
The library is pretty easy and straightforward to use.
// Create a custom class to hold an IDclassMyGeospatialPointextendsSimpleGeospatialPoint{privateintid;MyGeospatialPoint(doublelat,doublelon){super(lat,lon);}intgetId(){returnid;}}// Init Vantage-point tree and elements to itVPTree<SimpleGeospatialPoint>jeospatialPoints=newVPTree<>();for(inti=0;i<3000;i++){finaldoublelatitude=ThreadLocalRandom.current().nextDouble(50.4D,51.4D);finaldoublelongitude=ThreadLocalRandom.current().nextDouble(8.2D,11.2D);jeospatialPoints.add(newMyGeospatialPoint(latitude,longitude));}// Get the neareset neighbor for a given pointfinaldoublelatitude=ThreadLocalRandom.current().nextDouble(50.4D,51.4D);finaldoublelongitude=ThreadLocalRandom.current().nextDouble(8.2D,11.2D);varneighbor=(MyGeospatialPoint)jeospatialPoints.getNearestNeighbor(newMyGeospatialPoint(latitude,longitude),100*1000);varid=neighbor.getId();
It is much more clear than the Lucene’s example: init a VPTree, add points, perform a query. The simplicity doesn’t come without cost, of course - the library is somewhat limited in functionality and can be only to solve k-nearest-neighbor problem. Which is perfectly fine for me, because this is exactly what I needed.
As VPTree can hold only objects of GeospatialPoint type, to attach additional data to objects stored in the index we need to create another class that extends its only implementation SimpleGeospatialPoint and holds required data. Pay attention that getNearestNeighbor accepts as a second argument the distance in meters.
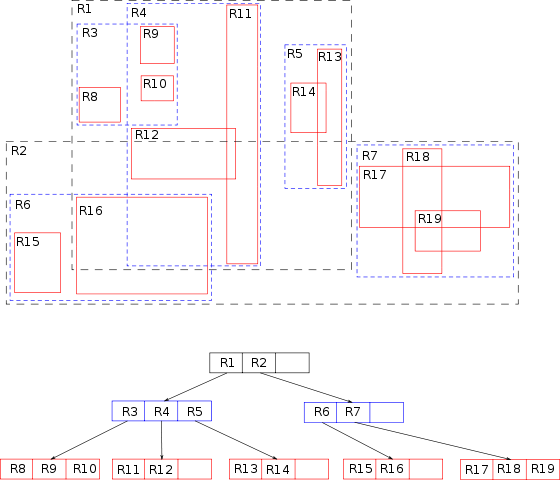
Figure 3. An example of an R-tree for 2D rectangles. Image courtesy of Wikipedia.
The main element behind this data structure is a minimum bounding rectangle . The “R” in R-tree stands for
rectangle. Each rectangle describes a single object, and nearby rectangles are then grouped in another
rectangle on a higher level. That’s a lot of rectangles in one sentence!
Alright, enough jokes, let’s have a look at the code example:
finalRTreertree=newRTree();rtree.init(null);// Index some pointsvarr=newRandom();for(inti=0;i<3000;i++){finaldoublelatitude=ThreadLocalRandom.current().nextDouble(50.4D,51.4D);finaldoublelongitude=ThreadLocalRandom.current().nextDouble(8.2D,11.2D);finalvarrect=newRectangle((float)latitude,(float)longitude,(float)latitude,(float)longitude);rtree.add(rect,r.nextInt());}// Perform a queryfinalfloatlatitude=(float)ThreadLocalRandom.current().nextDouble(50.4D,51.4D);finalfloatlongitude=(float)ThreadLocalRandom.current().nextDouble(8.2D,11.2D);finalvars=newPoint(latitude,longitude);finalvardistDegree=(float)DistanceUtils.dist2Degrees(100,DistanceUtils.EARTH_MEAN_RADIUS_KM);finalvaratomicId=newAtomicInteger();rtree.nearest(s,v->{atomicId.set(v);returntrue;},distDegree);varid=atomicId.get();
To be honest, the code was a bit confusing for me to write, because:
Rectangles everywhere. We need to index geo points, but the library supports only rectangles, so we have to create a “fake” rectangles with the same latitude and longitude for both corners.
Distance argument in “nearest”. The distance argument to rtree.nearest is a spherical distance in degrees. Here we convert 100km to degrees using Lucene’s DistanceUtils class :) Or, you can just put 0.89932036.
Usage of AtomicInteger. This is required, because rtree.nearest requires a lambda for each result. To use a variable inside a lambda it has to be effectively final, which does not allow us to change it, but we change an object’s state. Yeah, whatever.
I ran some benchmarks with all of above implementations. Worth noting, that I measure only querying performance, and not indexing. The reason is that my application should be optimized for read load, and it is totally fine if building indices takes some time. Of course, you can easily adjust the code to benchmark also the indexing phase.
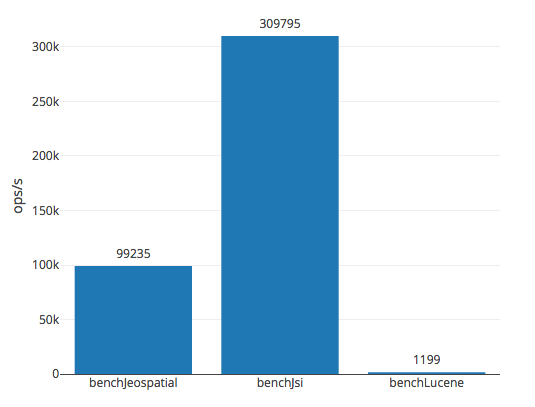
In preparation step, we create 3000 random geo points and store them in the index. During the benchmark itself, we perform a query against the index to find the nearest neighbour within 100 km. The full source code for benchmarks you can find in my GitHub repository. Here are the results.
To be honest, I was kind of surprised to find out, that Lucene performed so badly. It could be because a) its RAMDirectory is just slow or b) I cannot cook it. My guess - some misconfiguration, though I could not figure out what was wrong. I asked a question on StackOverflow, but so far no answers.
]]>Alexander GuzEnabling Trace Logging for Elasticsearch REST Client with Logback2018-09-30T15:12:00+02:002018-09-30T15:12:00+02:00https://guzalexander.com/2018/09/30/es-rest-client-trace-loggingRecently I had some issues with Elasticsearch - all requests were failing with “bad request” error. In order to understand what was wrong with these requests, I, natually, decided to enable debug/trace logging of for ES REST Client, but couldn’t find out how. Partially, because the official documentation on this topic could have been more informative, to be honest. But mainly, because my project uses Logback and the REST Client package uses Apache Commons Logging.
This article is a short summary of how I’ve eventually managed to enable tracing with Logback. The patient under inspection is Elasticsearch 6.3 with its Java Low Level REST Client.
According to the official documentation, we need to enable trace logging for the tracer package. If you are interested, you can check the source code for org.elasticsearch.client.RequestLogger class, where the logger with this name is defined:
As you can see, enabling this logger with TRACE level in Logback is not enough, because, again, the client uses Apache Commons Logging.
Luckily, Logback was designed with this use case in mind, and provides a set of bridging modules. They
allow us to use Logback even with other dependencies that rely on other logging API. In particular, we’re looking for jcl-over-slf4j.jar.
So, here are the steps.
Require jcl-over-slf4j.jar. The dependencies section for Gradle:
<configuration><appendername="STDOUT"class="ch.qos.logback.core.ConsoleAppender"><encoder><pattern>[%d{ISO8601}] [%thread] %-5level %logger{36} - %msg%n</pattern></encoder></appender><rootlevel="WARN"><appender-refref="STDOUT"/></root><loggername="tracer"level="TRACE"additivity="false"><appender-refref="STDOUT"/></logger><!-- Additionally, you can also enable debug logging ofr RestClient class itself --><loggername="org.elasticsearch.client.RestClient"level="DEBUG"additivity="false"><appender-refref="STDOUT"/></logger></configuration>