One of my recent tasks included searching for objects within some radius based on their geo coordinates. For various reasons — not relevant to this topic — I wanted to make this work completely in memory. That’s why solutions like MySQL Spatial Data Types, PostGIS or Elasticsearch Geo Queries were not considered. The project is in Java. I started to look for possible options, and, though, I found a few, they all lacked an easy to follow documentation (if at all) and examples.
So I decided to make a short description of some Java in-memory geospatial indices I’ve discovered during my research with code examples and benchmarks done with jmh.
Again, the task at hand: given a geo point, find the nearest to it object within a given radius using in-memory data structures. As an extra requirement, we would like to have arbitrary data attached to the objects stored in this data structures. The reason is that, in most cases, these objects are not merely geo points, they are rather some domain entities, and we would build our business logic based on them. In our case, the arbitrary data will be just an integer ID, and we pretend we can later fetch required entity from some repository by this ID.
Lucene spatial extras
I learned about Lucene while using Elasticsearch, because it’s based on it. I thought: well, Elasticsearch has Geo queries made with Lucene, which means Lucene has support for it, which, maybe, also has support for in-memory geospatial index. And I was right. Lucene project has Spatial-Extras module, that encapsulates an approach to indexing and searching based on shapes.
Using this module turned out to be a non-trivial task. Except JavaDocs and source code, I could only find an example of its usage in Apache Solr + Lucene repository, and made my implementation based on it. Lucene provides generalised approach to indexing and searching different types of data, and geospatial index is just one of the flavours.
Let’s have a look at the example.
final SpatialContext spatialCxt = SpatialContext.GEO;
final ShapeFactory shapeFactory = spatialCxt.getShapeFactory();
final SpatialStrategy coordinatesStrategy =
new RecursivePrefixTreeStrategy(new GeohashPrefixTree(spatialCxt, 5), "coordinates");
// Create an index
final Directory directory = new RAMDirectory();
IndexWriterConfig iwConfig = new IndexWriterConfig();
IndexWriter indexWriter = new IndexWriter(directory, iwConfig);
// Index some documents
var r = new Random();
for (int i = 0; i < 3000; i++) {
double latitude = ThreadLocalRandom.current().nextDouble(50.4D, 51.4D);
double longitude = ThreadLocalRandom.current().nextDouble(8.2D, 11.2D);
Document doc = new Document();
doc.add(new StoredField("id", r.nextInt()));
var point = shapeFactory.pointXY(longitude, latitude);
for (var field : coordinatesStrategy.createIndexableFields(point)) {
doc.add(field);
}
doc.add(new StoredField(coordinatesStrategy.getFieldName(), latitude + ":" + longitude));
indexWriter.addDocument(doc);
}
indexWriter.forceMerge(1);
indexWriter.close();
// Query the index
final IndexReader indexReader = DirectoryReader.open(directory);
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
double latitude = ThreadLocalRandom.current().nextDouble(50.4D, 51.4D);
double longitude = ThreadLocalRandom.current().nextDouble(8.2D, 11.2D);
final double NEARBY_RADIUS_DEGREE = DistanceUtils.dist2Degrees(100, DistanceUtils.EARTH_MEAN_RADIUS_KM);
final var spatialArgs = new SpatialArgs(SpatialOperation.IsWithin,
shapeFactory.circle(longitude, latitude, NEARBY_RADIUS_DEGREE));
final Query q = coordinatesStrategy.makeQuery(spatialArgs);
try {
final TopDocs topDocs = indexSearcher.search(q, 1);
if (topDocs.totalHits == 0) {
return;
}
var doc = indexSearcher.doc(topDocs.scoreDocs[0].doc);
var id = doc.getField("id").numericValue();
} catch (IOException e) {
e.printStackTrace();
}In order to use it we need:
- Create an index. At this step you can choose where to store the index. For our use case, there is a RAMDirectory, which is essentially in-memory storage. This class is marked as deprecated, because it uses inefficient synchronization according to the documentation. This might explain its poor performance. But we’ll come back to this later.
- Index some documents. To make our index support geospatial queries we need to have a field of type Shape, in particular Point in our document.
- Query the index. Perform a spatial operation against the index.
Oh my gosh! That’s a good deal of classes to consider! That is definitely not the winner of the contest on “The most clear and easy to use API”. Though, as you would expect, Lucene indices are the most flexible:
- Provides various shapes implementations: point, rectangle, and circle. You can also teach it to support polygons with some additional dependency.
- You can put any data to the indexed document along with its geo point. It means you can store the whole entity there and perform other queries supported by Lucene, for example, fuzzy text matching.
- Supports various spartial operations: is within, contains, intersects, etc. Check SpatialOperation.
- It has distance and other spatial related math calculations.
Jeospatial
Jeospatial is a geospatial library that provides a set of
tools for solving the k-nearest-neighbor problem on the earth’s surface. It is implemented using
Vantage-point trees, and claims to have O(n log(n))
time complexity for indexing operations and O(log(n))— for searching. A great visual explanation of how Vantage-point trees are constructed with examples can be found in this article.

The library is pretty easy and straightforward to use.
// Create a custom class to hold an ID
class MyGeospatialPoint extends SimpleGeospatialPoint {
private int id;
MyGeospatialPoint(double lat, double lon) {
super(lat, lon);
}
int getId() {
return id;
}
}
// Init Vantage-point tree and elements to it
VPTree<SimpleGeospatialPoint> jeospatialPoints = new VPTree<>();
for (int i = 0; i < 3000; i++) {
final double latitude = ThreadLocalRandom.current().nextDouble(50.4D, 51.4D);
final double longitude = ThreadLocalRandom.current().nextDouble(8.2D, 11.2D);
jeospatialPoints.add(new MyGeospatialPoint(latitude, longitude));
}
// Get the neareset neighbor for a given point
final double latitude = ThreadLocalRandom.current().nextDouble(50.4D, 51.4D);
final double longitude = ThreadLocalRandom.current().nextDouble(8.2D, 11.2D);
var neighbor = (MyGeospatialPoint) jeospatialPoints.getNearestNeighbor(new MyGeospatialPoint(latitude, longitude), 100 * 1000);
var id = neighbor.getId();It is much more clear than the Lucene’s example: init a VPTree, add points, perform a query. The simplicity doesn’t come without cost, of course - the library is somewhat limited in functionality and can be only to solve k-nearest-neighbor problem. Which is perfectly fine for me, because this is exactly what I needed.
As VPTree can hold only objects of GeospatialPoint type, to attach additional data to objects stored in the index we need to create another class that extends its only implementation SimpleGeospatialPoint and holds required data. Pay attention that getNearestNeighbor accepts as a second argument the distance in meters.
More info can be found in the official GitHub repository.
The Java Spatial Index
The Java Spatial Index is a Java version of the R-tree spatial indexing algorithm as described in the 1984 paper “R-trees: A Dynamic Index Structure for Spatial Searching” by Antonin Guttman.
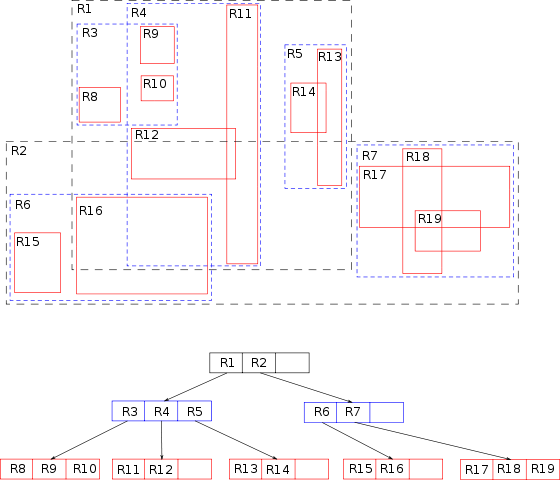
The main element behind this data structure is a minimum bounding rectangle . The “R” in R-tree stands for rectangle. Each rectangle describes a single object, and nearby rectangles are then grouped in another rectangle on a higher level. That’s a lot of rectangles in one sentence!

Alright, enough jokes, let’s have a look at the code example:
final RTree rtree = new RTree();
rtree.init(null);
// Index some points
var r = new Random();
for (int i = 0; i < 3000; i++) {
final double latitude = ThreadLocalRandom.current().nextDouble(50.4D, 51.4D);
final double longitude = ThreadLocalRandom.current().nextDouble(8.2D, 11.2D);
final var rect = new Rectangle((float) latitude, (float) longitude,
(float) latitude, (float) longitude);
rtree.add(rect, r.nextInt());
}
// Perform a query
final float latitude = (float) ThreadLocalRandom.current().nextDouble(50.4D, 51.4D);
final float longitude = (float) ThreadLocalRandom.current().nextDouble(8.2D, 11.2D);
final var s = new Point(latitude, longitude);
final var distDegree = (float) DistanceUtils.dist2Degrees(100, DistanceUtils.EARTH_MEAN_RADIUS_KM);
final var atomicId = new AtomicInteger();
rtree.nearest(s, v -> {
atomicId.set(v);
return true;
}, distDegree);
var id = atomicId.get();To be honest, the code was a bit confusing for me to write, because:
- Rectangles everywhere. We need to index geo points, but the library supports only rectangles, so we have to create a “fake” rectangles with the same latitude and longitude for both corners.
- Distance argument in “nearest”. The distance argument to rtree.nearest is a spherical distance in degrees. Here we convert 100km to degrees using Lucene’s DistanceUtils class :) Or, you can just put 0.89932036.
- Usage of AtomicInteger. This is required, because rtree.nearest requires a lambda for each result. To use a variable inside a lambda it has to be effectively final, which does not allow us to change it, but we change an object’s state. Yeah, whatever.
You can find more examples in the repository.
Benchmarks
I ran some benchmarks with all of above implementations. Worth noting, that I measure only querying performance, and not indexing. The reason is that my application should be optimized for read load, and it is totally fine if building indices takes some time. Of course, you can easily adjust the code to benchmark also the indexing phase.
In preparation step, we create 3000 random geo points and store them in the index. During the benchmark itself, we perform a query against the index to find the nearest neighbour within 100 km. The full source code for benchmarks you can find in my GitHub repository. Here are the results.
java -jar target/benchmarks.jar -foe true -rf csv -rff benchmark.csv
...
Benchmark Mode Cnt Score Error Units
MyBenchmark.benchJeospatial thrpt 3 99235,728 ± 132352,814 ops/s
MyBenchmark.benchJsi thrpt 3 309795,462 ± 202296,631 ops/s
MyBenchmark.benchLucene thrpt 3 1199,864 ± 1199,138 ops/sAnd visual representation.
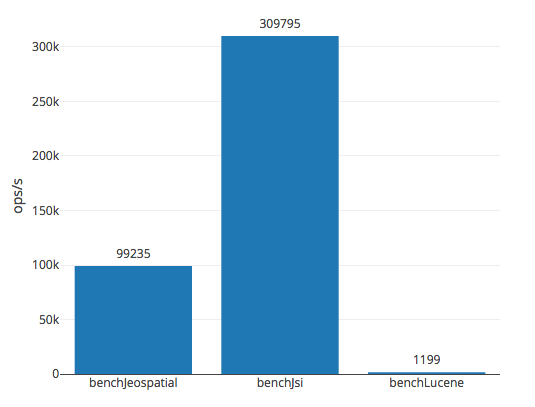
To be honest, I was kind of surprised to find out, that Lucene performed so badly. It could be because a) its RAMDirectory is just slow or b) I cannot cook it. My guess - some misconfiguration, though I could not figure out what was wrong. I asked a question on StackOverflow, but so far no answers.